Categories: Artificial Intelligence, Computer Vision, Audio Processing
Tags: Sonic, audio-driven animation, portrait animation, global audio perception, CVPR 2025, deep learning
Introduction
In today's rapidly evolving digital content creation and artificial intelligence landscape, audio-driven portrait animation technology is experiencing a revolutionary transformation. Recently, the "Sonic" technology developed by Tencent's research team has garnered widespread attention from both academia and industry. This research, accepted by CVPR 2025, proposes a novel paradigm focused on global audio perception, capable of generating high-quality, temporally coherent, and expressive portrait animations without any visual motion guidance.
Why Audio-Driven Animation Matters
Traditional talking face generation techniques often rely on visual motion cues, which not only increase production costs but may also introduce identity bias. Sonic's breakthrough lies in:
- Pure Audio-Driven: Requires only audio input and a reference image to generate animations
- Long Video Stability: Supports stable long video generation from 1-10 minutes
- Strong Generalization: Applicable to real humans, cartoon characters, and multiple resolutions
Sonic Technology Core: The Innovation Paradigm of Global Audio Perception
What is Global Audio Perception?
Sonic's core innovation lies in decomposing global audio perception into two key dimensions:
1. Intra-clip Audio Perception
Focuses on immediate features and changes within individual audio clips, including phoneme pronunciation, prosody-driven facial expression changes, and other detailed processing.
2. Inter-clip Audio Perception
Focuses on connections and transitions between different audio clips, ensuring animation coherence and stability over long time spans.
Sonic's Three Core Technical Pillars
| Component Name | Perception Type | Key Function | Utilized Audio Features |
|---|---|---|---|
| Context-enhanced Audio Learning | Intra-clip | Extract long-range temporal audio knowledge to provide priors for facial expressions and lip movements | Tone, speaking rate, prosody |
| Motion-decoupled Controller | Intra-clip | Decouple and independently control head motion and expression motion based on audio | Various audio cues driving head/expression |
| Time-aware Position Shift Fusion | Inter-clip | Fuse global inter-clip audio information through offset windows for long audio reasoning | Temporal continuity, long-range context |
Technical Deep Dive
1. Context-enhanced Audio Learning
This component goes beyond simple phoneme-to-viseme mapping by considering broader prosodic features within audio clips, enabling:
- Precise synchronization guidance for lip movements
- Natural changes in facial expressions
- Linking suprasegmental features of speech (emotion, stress, intonation) with visual representation
2. Motion-decoupled Controller
By separating head motion from facial expression processing, it achieves:
- More refined motion control
- More natural, less rigid animation effects
- Differential influence of different aspects of audio signals on motion types
3. Time-aware Position Shift Fusion
Serving as the "bridge" for achieving global perception, this mechanism:
- Ensures animation coherence in long audio sequences
- Employs sliding window methods to maintain and update contextual information
- Effectively avoids error accumulation in long sequence generation

Practical Application Steps
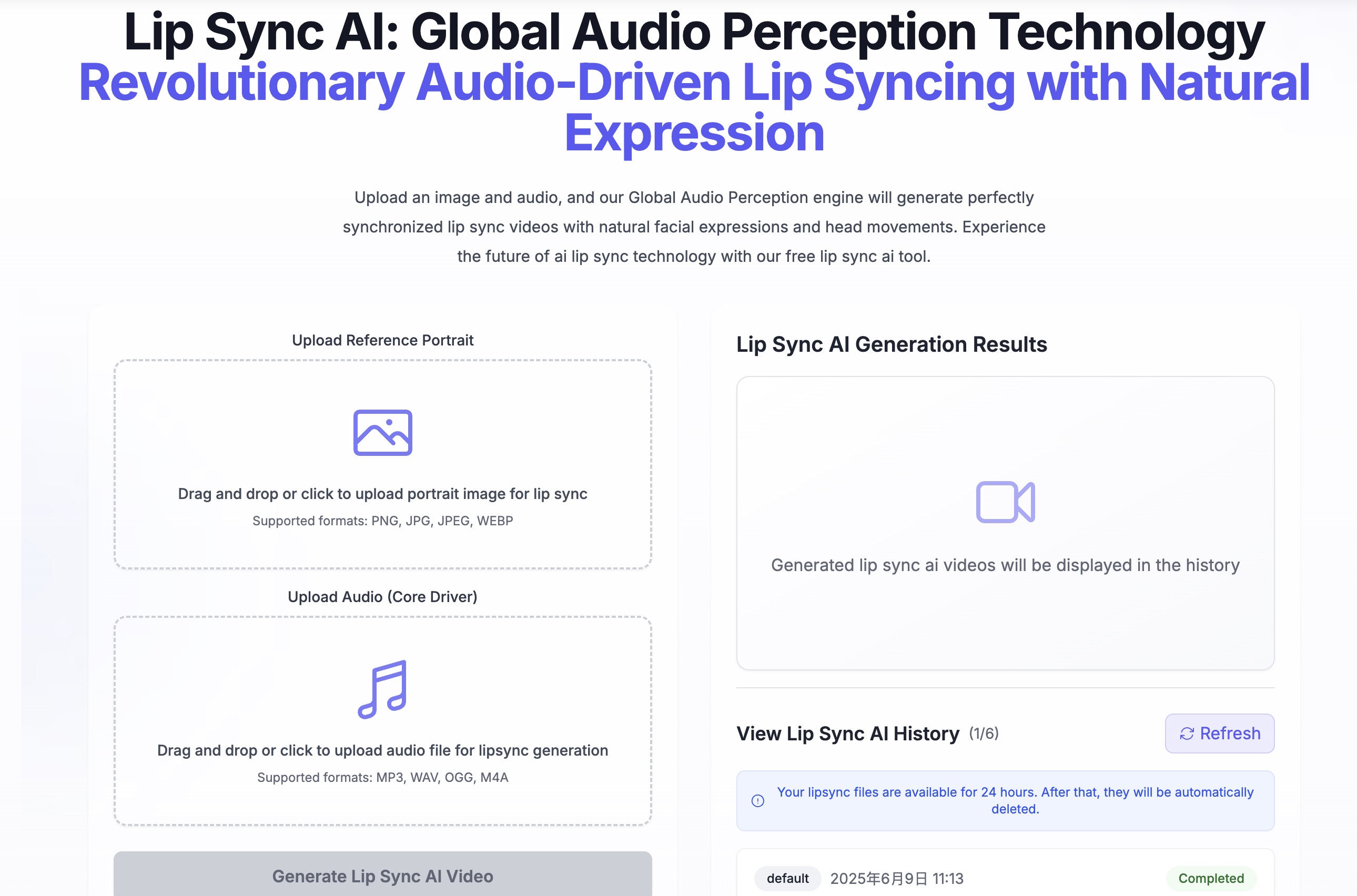
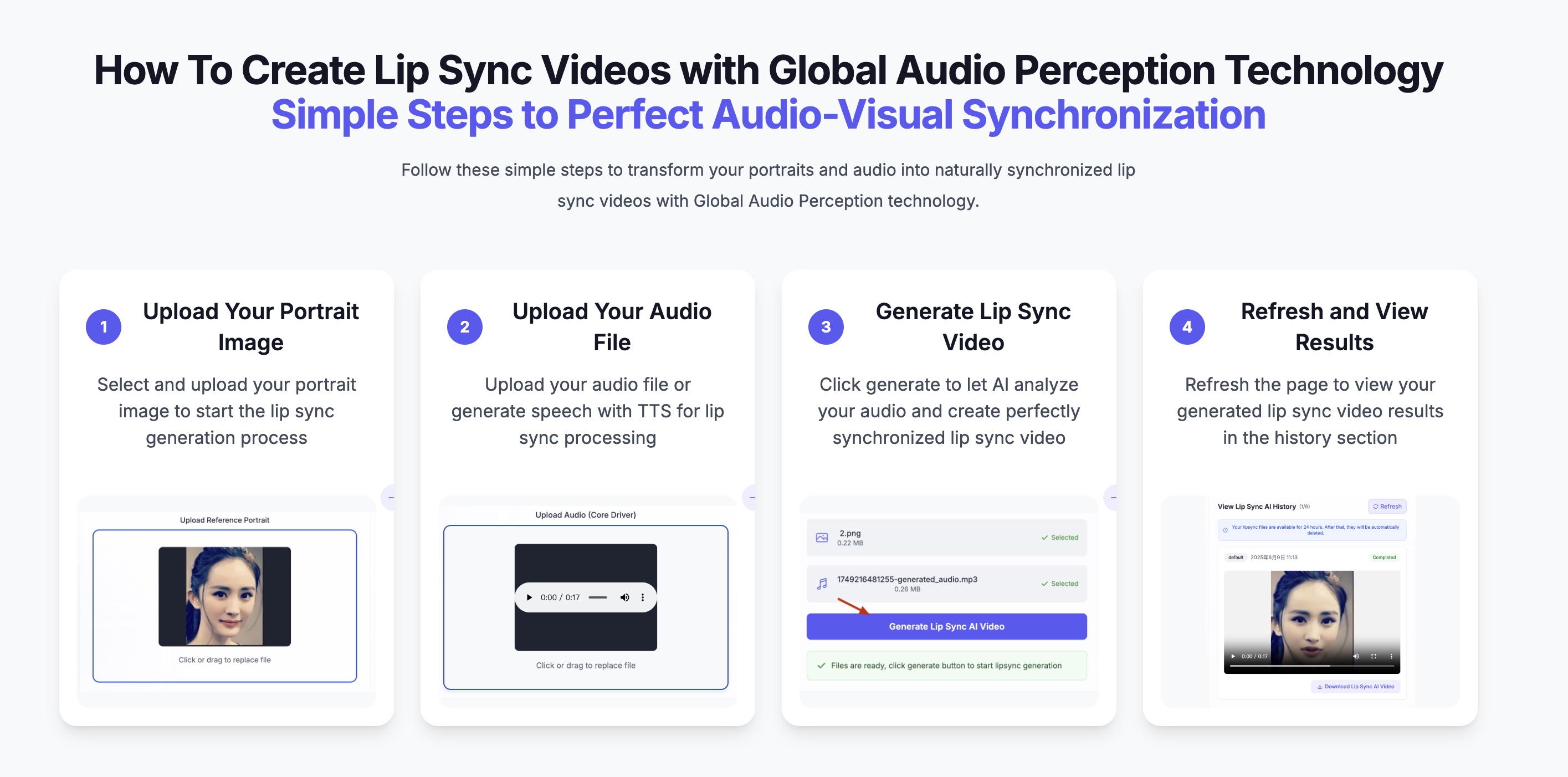
How to Create Portrait Animation with Sonic
Step 1: Prepare Input Materials
- Select high-quality audio files (WAV format recommended)
- Prepare clear reference portrait images
Step 2: Audio Preprocessing
- Ensure audio is clear with minimal noise
- Adjust audio length as needed (supports 1-10 minutes)
Step 3: Model Inference
- Input audio and reference image into Sonic model
- Model automatically performs global audio perception analysis
Step 4: Animation Generation
- System generates temporally coherent portrait animation
- Supports real-time generation progress viewing
Step 5: Output Export
- Export high-quality video files
- Supports multiple resolutions and formats
Expert Opinions
"Sonic represents an important milestone in the audio-driven animation field. Its global audio perception approach addresses the temporal consistency issues that have long plagued this domain." – Xiaozhong Ji, Sonic Project Lead
"Being able to generate stable animations up to 10 minutes long using only audio and a single static image was previously unimaginable. Sonic's breakthrough opens up entirely new possibilities for content creators." – Xiaobin Hu, Computer Vision Expert
Common Pitfalls to Avoid
When using audio-driven animation technology, be aware of these common issues:
- Over-reliance on Visual Cues: Sonic's advantage lies in pure audio-driven approach; don't attempt to add additional visual constraints
- Ignoring Audio Quality: Poor audio quality directly affects animation results; use clear recordings
- Expecting Over-control: While supporting decoupled control, excessive manual adjustments may compromise naturalness
Performance Advantage Comparison
Sonic vs Traditional Methods
| Metric | Sonic | Traditional Methods |
|---|---|---|
| Video Quality | Significant Improvement | Baseline Level |
| Temporal Consistency | Excellent | Prone to Drift |
| Lip Sync Accuracy | High Precision | Moderate Precision |
| Motion Diversity | Rich and Natural | Relatively Limited |
| Long Video Stability | Supports 10+ minutes | Usually <1 minute |
Application Scenario Prospects
Sonic technology has extremely broad application prospects:
1. Virtual Anchors and Digital Humans
Provide vivid virtual characters for streaming platforms and corporate presentations
2. Educational Content Creation
Automatically generate instructor animations for online courses and explanatory videos
3. Film and TV Post-production
Enhance lip-sync quality for dubbed content
4. Gaming and Metaverse
Create diverse interactive characters
Conclusion
The emergence of Sonic technology marks a major breakthrough in the audio-driven portrait animation field. Through its innovative global audio perception paradigm, it not only addresses the limitations of traditional methods in temporal consistency and long video generation but also opens new pathways for pure audio-driven, high-quality animation production.
With the open-source release of this technology and active community participation, we can expect Sonic to become an important foundation for future audio-driven animation research and applications, driving the entire industry toward more intelligent and efficient directions.
Call to Action
Ready to experience next-generation audio-driven animation technology? Visit the Sonic project homepage now and explore how this revolutionary technology can bring unlimited possibilities to your creative work!
Suggested Internal Links
- Deep Learning Applications in Video Generation
- AI-Driven Content Creation Tools
- Audio Processing Technology Progress Review
Suggested External Links
FAQs
1. What input formats does Sonic support?
Supports common audio formats (WAV, MP3, etc.) and image formats (JPG, PNG, etc.).
2. What's the maximum video length that can be generated?
Currently supports stable long video generation from 1-10 minutes.
3. Does it support real-time generation?
The current version is mainly for offline processing; real-time version is under development.
4. What are the hardware requirements?
Recommend using GPUs with sufficient VRAM; specific configurations can be found in the official documentation.
Social Media Snippet:
🎭✨ Revolutionary Sonic audio-driven animation technology is here! Generate 10-minute high-quality portrait animations with just audio + one image. CVPR 2025 accepted, new global audio perception paradigm! #Sonic #AIAnimation #AudioDriven
By following these guidelines and leveraging Sonic's powerful capabilities, you can create engaging portrait animation content that adds professional-grade visual effects to your projects. Start your creative journey today!